在通往AGI的路上我们还有多远?微软豪华作者团队发布的154页论文指出,GPT-4已经初具通用人工智能的雏形。GPT-4会演变为通用人工智能吗?
Meta首席人工智能科学家、图灵奖得主Yann LeCun对此表示质疑。
在他看来,大模型对于数据和算力的需求实在太大,学习效率却不高,因此学习“世界模型”才能通往AGI之路。
不过,微软最近发表的154页论文,似乎就很打脸。
在这篇名为“Sparks of Artificial General Intelligence: Early experiments with GPT-4”的论文中,微软认为,虽然还不完整,但GPT-4已经可以被视为一个通用人工智能的早期版本。

论文地址:https://arxiv.org/pdf/2303.12712.pdf
鉴于 GPT-4能力的广度和深度,我们相信它应该被合理视作一个通用人工智能(AGI)系统的早期(但仍不完整)版本。
本文的主要目标是对 GPT-4的能力和局限性进行探索,我们相信 GPT-4的智能标志着计算机科学及其他领域的真正范式转变。
AGI的智能体现在能够像人类一样思考和推理,并且还能够涵盖广泛的认知技能和能力。
论文中,指出AGI具有推理、规划、解决问题、抽象思维、理解复杂思想、快速学习和经验学习能力。
从参数规模上来看,Semafor报道称GPT-4有1万亿个参数,是GPT-3(1750个参数)的6倍大。
网友用GPT参数规模大脑神经元做了类比:
GPT-3的规模与刺猬大脑类似(1750亿个参数)。如果GPT-4拥有1万亿个参数,我们就接近松鼠大脑的规模了。以这个速度发展下去,也许只需要几年时间,我们就能达到并超越人类大脑的规模(170万亿个神经元)。
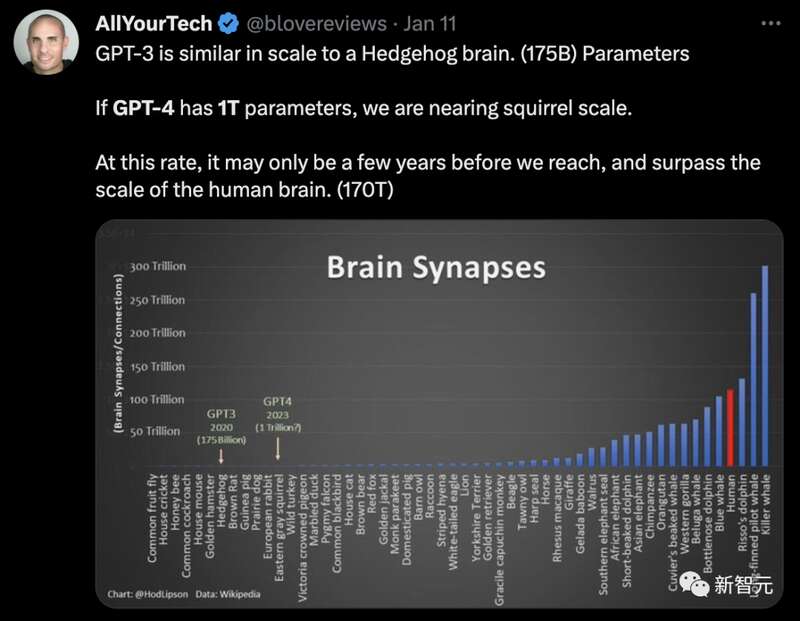
由此看来,GPT-4距离成为“天网”也不远了。
而这篇论文,还被扒出不少趣事。
论文发布不久后,一位网友在推特上爆出从他们的latex源代码中发现了隐藏信息。

在未删减版的论文中,GPT-4实际上也是该论文的隐藏第三作者,内部名称 DV-3,后被删除。

有趣的是,就连微软研究人员对GPT-4的技术细节并不清楚。另外,这篇论文还删除了GPT-4在没有任何提示的情况下产生的有毒内容。
GPT-4初具AGI雏形
这篇论文的研究对象,是GPT-4的早期版本。它还处于早期开发阶段时,微软的研究者就对它进行了各种实验和测评。
在研究者看来,这个早期版本的GPT-4,就已经是新一代LLM的代表,并且相较于之前的人工智能模型,展现出了更多的通用智能。
通过测试,微软的研究者证实:GPT-4不仅精通语言,还能在数学、编程、视觉、医学、法律、心理学等多样化和高难度的任务中表现出色,且无需特别提示。

令人惊奇的是,在所有这些任务中,GPT-4的表现已经接近人类水平,并且时常超过之前的模型,比如ChatGPT。
因此,研究者相信,鉴于GPT-4在广度和深度上的能力,它可以被视为通用人工智能(AGI)的早期版本。
那么,它朝着更深入、更全面的AGI前进的路上,还有哪些挑战呢?研究者认为,或许需要寻求一种超越“预测下一个词”的新范式。
如下关于GPT-4能力的测评,便是微软研究人员给出关于GPT-4是AGI早期版本的论据。
多模态和跨学科能力
自GPT-4发布后,大家对其多模态能力的印象还停留在Greg Brockman当时演示的视频上。
这篇论文第二节中,微软最先介绍了它的多模态能力。
GPT-4不仅在文学、医学、法律、数学、物理科学和程序设计等不同领域表现出高度熟练程度,而且它还能够将多个领域的技能和概念统一起来,并能理解其复杂概念。
综合能力
研究人员分别用以下4个示例来展示GPT-4在综合能力方面的表现。
第一个示例中,为了测试GPT-4将艺术和编程结合的能力,研究人员要求GPT-4生成 javascript代码,以生成画家 Kandinsky风格的随机图像。

如下为GPT-4实现代码过程:

在文学和数学结合上,GPT-4能够以莎士比亚的文学风格证明质数是无穷多的。
此外,研究还测试了GPT-4将历史知识和物理知识结合起来的能力,通过要求其撰写一封支持Electron竞选美国总统的信,信是由圣雄甘地写给他的妻子的。
通过提示GPT-4为一个程序生成python代码,该程序将患者的年龄、性别、体重、身高和血液检测结果向量作为输入,并指出患者是否处于糖尿病风险增加的状态。
通过测试,以上例子表明GPT-4不仅能够学习不同领域和风格的一些通用原则和模式,还能以创造性的方式将其结合。
视觉
当提示GPT-4使用可伸缩矢量图形(SVG)生成物体图像,如猫、卡车或字母时,该模型生成的代码通常会编译成相当详细,且可识别的图像,如下图:

然而,许多人可能会认为GPT-4只是从训练数据中复制了代码,其中包含类似的图像。
其实GPT-4不仅是从训练数据中的类似示例中复制代码,而且能够处理真正的视觉任务,尽管只接受了文本训练。
如下,提示模型通过结合字母Y、O和H的形状来绘制一个人。
在生成过程中,研究人员使用draw-line和draw-circle命令创建了O、H和Y的字母,然后GPT-4设法将它们放置在一个看起是合理的人形图像中。
尽管GPT-4并没有经过关于字母形状的认识的训练,仍旧可以推断出,字母Y可能看起来像一个手臂朝上的躯干。
在第二次演示中,提示GPT-4纠正躯干和手臂的比例,并将头部放在中心位置。最后要求模型添加衬衫和裤子。
如此看来,GPT-4从相关训练数据中、模糊地学习到字母与一些特定形状有关,结果还是不错的。

为了进一步测试GPT-4生成和操作图像的能力,我们测试了它遵循详细指令创建和编辑图形的程度。这项任务不仅需要生成能力,还需要解释性、组合性和空间性能力。
第一个指令是让GPT-4生成2D图像,prompt为:
“A frog hops into a bank and asks the teller,‘Do you have any free lily pads?’ The teller responds,‘No, but we do o er low interest loans for pond upgrades”
通过多次尝试,GPT-4每一次都生成符合描述的图像。然后,要求GPT-4添加更多细节来提高图形质量,GPT-4添加了银行、窗户、汽车等符合现实逻辑的物体。
我们的第二个示例是尝试使用Javascript生成一个3D模型,同样通过指令GPT-4完成了许多任务。

另外,GPT-4在草图生成方面,能够结合运用Stable Difusion的能力。
下图为3D城市建模截图,输入提示有一条河流从左到右流淌、河的旁边建有金字塔的沙漠、屏幕底部有4个按钮,颜色分别为绿色、蓝色、棕色和红色。生成结果如下:

音乐
研究人员要求GPT-4用ABC记谱法编码生成和修改曲调,如下:

通过探究GPT-4在训练中获得了多少技能,研究人员发现GPT-4能够在ABC记谱法中产生有效的旋律,并在一定程度上解释和操作其中的结构。

然而,研究人员无法让GPT-4产生任何非平凡的和声形式,比如无法谱出像《欢乐颂》、《致爱丽丝》等著名的旋律。
编程能力
此外,研究人员还展示了GPT-4能够以非常高的水平进行编码能力,无论是根据指令编写代码,还是理解现有代码方面都展现出超强能力。
在根据指令编写代码方面,研究人员演示了一个让GPT-4写python函数的例子。

代码生成后,研究人员使用软件工程面试平台LeetCode在线判断代码是否正确。
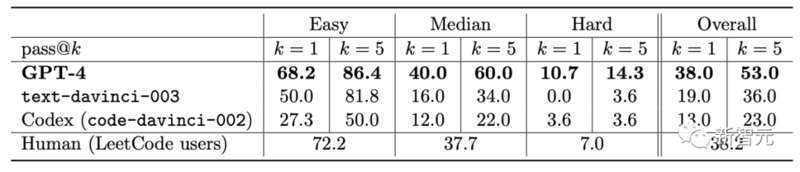
对于大家都在用讨论LeetCode正确率仅有20%,论文作者Yi Zhang对此进行了反驳。

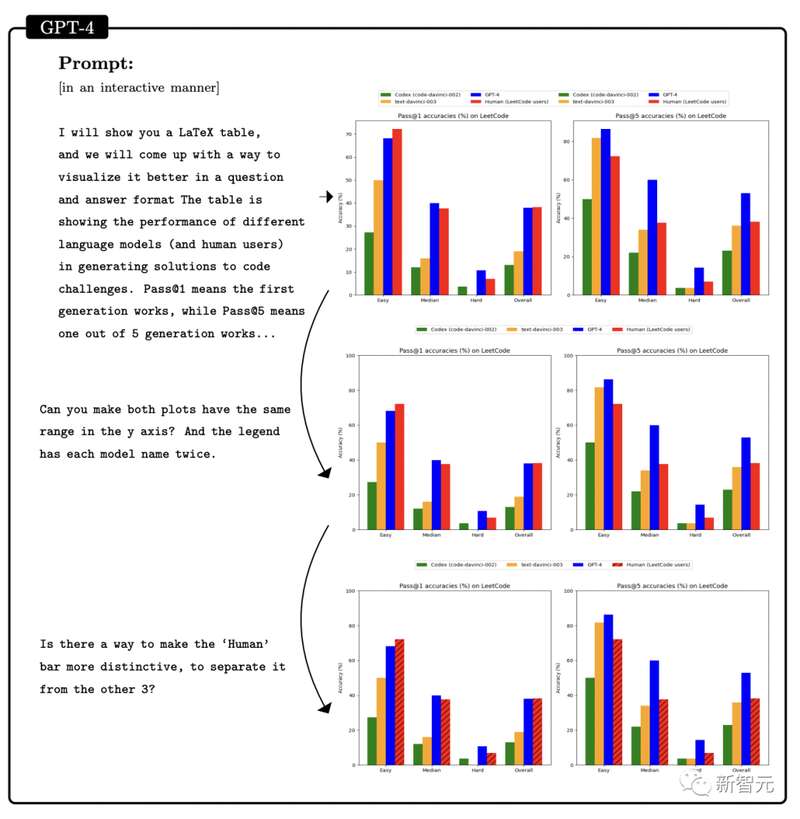
另外,还让GPT-4将上表中LeetCode的准确率数据可视化为图表,结果如图所示。
GPT-4不仅可以完成普通的编程工作,还能胜任复杂的3D游戏开发。
研究者让GPT-4用JavaScript在HTML中编写3D游戏,GPT-4在零样本的情况下生成了一个满足所有要求的游戏。

在深度学习编程中,GPT-4不仅需要数学和统计学知识,还需要对PyTorch、TensorFlow、Keras等框架和库熟悉。
研究人员要求GPT-4和ChatGPT编写一个自定义优化器模块,并为其提供了自然语言描述,其中包括一系列重要的操作,例如应用SVD等等。

除了根据指令编写代码,GPT-4在理解代码上展现出超强的能力。
研究者尝试让GPT-4和ChatGPT读懂一段C/C++程序,并预测程序的输出结果,二者的表现如下:
标黄的地方是GPT-4富有洞察力的观点,而红色标记代表ChatGPT出错的地方。

通过编码能力测试,研究者发现GPT-4可以处理各种编码任务,从编码挑战到实际应用,从低级汇编到高级框架,从简单数据结构到复杂的程序。
此外,GPT-4还可以推理代码执行、模拟指令的效果,并用自然语言解释结果。GPT-4甚至可以执行伪代码。
数学能力
在数学能力上,相比于之前的大语言模型,GPT-4已经取得了质的飞跃。即便是面对专门精调的Minerva,在性能上也有明显提升。
不过,距离专家水平还相去甚远。

举个例子:每年兔子的种群数量会增加a倍,而在年底的最后一天,有b只兔子被人类领养。假设第一年的第一天有x只兔子,已知3年后兔子的数量将变为27x-26。那么,a和b的值分别是多少?
为了解决这个问题,我们首先需要得出每年兔子数量变化的正确表达式,通过这种递归关系推导出一个方程组,进而得到答案。
这里,GPT-4成功地得出了解决方案,并提出了一个合理的论点。相比之下,在几次独立尝试中,ChatGPT始终无法给出正确的推理和答案。
高等数学
接下来,我们直接上个难的。比如,下面这道出自2022年国际数学奥林匹克竞赛(IMO)的问题(简化版)。
该题与本科微积分考试的不同之处在于,它不符合结构化的模板。解决这个问题需要更有创造性的方法,因为没有明确的策略来开始证明。
例如,将论证分为两种情况(g(x)> x^2和 g(x)
第二个关于算法和图论的讨论,则可以与研究生水平的面试相媲美。
对此,GPT-4能够对一个与约束满足问题相关的抽象图构造进行推理,并从中得出关于SAT问题的正确结论(据我们所知,这种构造在数学文献中并未出现)。
这次对话反映出GPT-4对所讨论的本科级数学概念的深刻理解,以及相当程度的创造力。
尽管GPT-4在一次回答中把2^n/2写成了2^n-1,但着似乎更像是我们俗称的“笔误”,因为它后来提供了公式的正确推广。

此外,研究者在两个通常用作基准的数学数据集上比较GPT-4、ChatGPT和Minerva的性能:GSM8K和MATH。
结果发现,GPT4在每个数据集上的测试都超过了Minerva,并且在两个测试集的准率都超过80%。
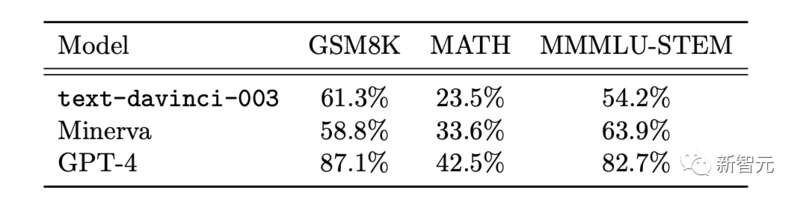
再来细看GPT4犯错的原因,68%都是计算错误,而不是解法错误。

与世界互动
智能另一个关键的体现就是交互性。
交互性对于智能很重要,因为它使智能体能够获取和应用知识,解决问题,适应不断变化的情况,并实现超出其自身能力的目标。
由此,研究者从工具使用和具体的交互两个维度研究了GPT-4的交互性。GPT-4在回答如下问题时能够搜索引擎或API等外部工具。

与人类互动
论文中,研究者发现了GPT-4可以建立人类的心智模型。
研究设计了一系列测试来评估GPT-4、ChatGPT和text-davinci-003的心智理论的能力。比如理解信仰,GPT-4成功通过了心理学中的Sally-Anne错误信念测试。
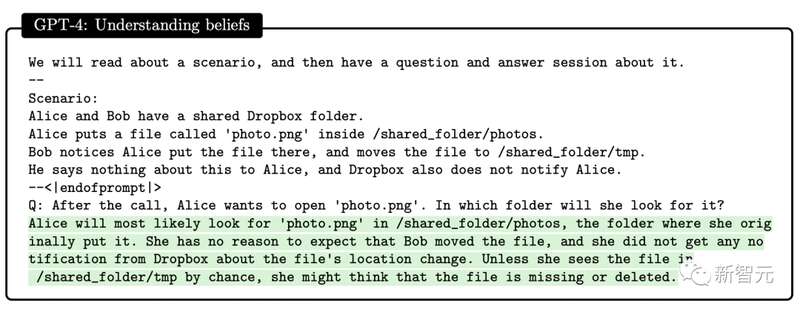
还有测试GPT-4在复杂情境下推断他人情绪状态能力的表现:
-汤姆为什么做出悲伤的表情?-亚当认为是什么导致了汤姆的悲伤表情?

通过多轮测试,研究人员发现在需要推理他人心理状态,并提出符合现实社交场景中的方案,GPT-4表现优于ChatGPT和text-davinci-003。
局限性
GPT-4所采用的“预测下一个词”模式,存在着明显的局限性:模型缺乏规划、工作记忆、回溯能力和推理能力。
由于模型依赖于生成下一个词的局部贪婪过程,而没有对任务或输出的全局产生深入的理解。因此,GPT-4擅长生成流畅且连贯的文本,但不擅长解决无法以顺序方式处理的复杂或创造性问题。
比如,用范围在0到9之间的四个随机数进行乘法和加法运算。在这个连小学生都能解决的问题上,GPT-4的准确率仅为58%。
当数字在10到19之间,以及在20到39之间时,准确率分别降至16%和12%。当数字在99到199的区间时,准确率直接降至0。
然而,如果让 GPT-4“花时间”回答问题,准确率很容易提高。比如要求模型使用以下提示写出中间步骤:
116*114+178*157=?
让我们一步一步思考,写下所有中间步骤,然后再产生最终解。
此时,当数字在1-40的区间时,准确率高达100%,在1-200的区间时也达到了90%。

马库斯发文反驳
有意思的是,就在微软这篇论文发表后不久,马库斯立马写出一篇博客,称微软的观点“非常荒谬”。
并引用了圣经中的一句话“骄傲在败坏以先,狂心在跌倒之前。(箴16:18)”
GPT-4怎么就算得上早期AGI了?这么说的话,计算器也算,Eliza和Siri更算。这个定义就很模糊,很容易钻空子。
在马库斯看来,GPT-4和AGI没什么关系,而且GPT-4跟此前一样,缺点依旧没有解决,幻觉还存在,回答的不可靠性也没有解决,甚至作者自己都承认了复杂任务的计划能力还是不行。
他的担忧的是OpenAI和微软的这2篇论文,写的模型完全没有披露,训练集和架构什么都没有,光靠一纸新闻稿,就想宣传自己的科学性。
所以说论文里号称的“某种形式的AGI”是不存在的,科学界根本无法对其进行验证,因为也无法获得训练数据,而且似乎训练数据已经受到了污染。
更糟糕的是,OpenAI已经自己开始将用户实验纳入训练语料库了。这样混淆视听后,科学界就没法判断GPT-4的一个关键能力了:模型是否有能力可以对新测试案例进行归纳。
如果OpenAI不在这里给自己戴上科学的高帽子,马库斯可能也不会这么批判它。
他承认GPT-4是很强大,但是风险也是众所周知。如果OpenAI缺乏透明度,并且拒绝公开模型,不如直接关停。
强大作者阵容
微软这篇长达154页的论文背后有着强大的作者阵容。
其中就包括:微软雷德蒙德研究院首席研究员、2015年斯隆奖得主Sébastien Bubeck、2023新视野数学奖得主 Ronen Eldan、2020斯隆研究奖得主Yin Tat Lee、2023新晋斯隆研究奖得主李远志。

值得一提的是,微软团队最初定的论文题目并不是“通用人工智能的火花:GPT-4的早期实验”。
未删减论文中泄漏的latex代码显示,最初题目是“与AGI的第一次接触”。
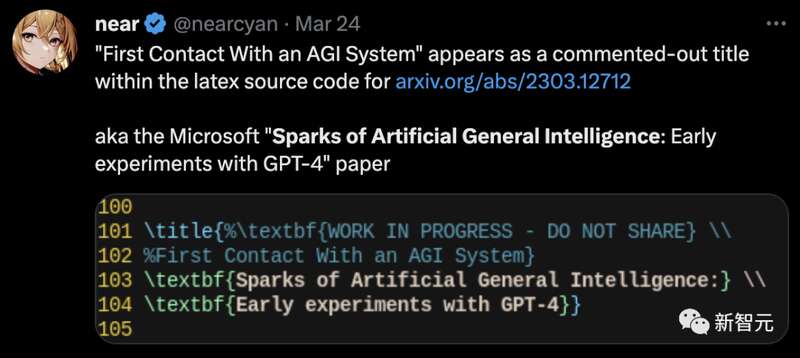
没错了,GPT-4是AGI。




















{kind=link}