
“微博崩了”“知乎崩了”“小红书崩了”我们都经历过。你能想象“微信崩了”是什么场景吗?
2021年1月18日下午,曾有诸多网友反映微信群聊、私信等收不到消息。“微信 bug”一度冲上热搜。腾讯微信团队回应:
“由于系统抖动原因,今天14点左右,部分微信用户遇到了消息收取延迟情况,现在已经修复完成。”
这次“系统抖动”影响的人数确实相对较少,而历史上,微信也只有朋友圈、红包等部分功能模块偶尔出现“崩了”的情况,相对来说算是“稳如泰山”。
但是,在刚刚过去的10月4日,除中国大陆以外的全球网友是切切实实体会到了一次什么叫他们的“微信”崩了。有着35亿活跃用户的 Facebook全线业务,一度在全球范围无法访问长达6小时。
这些服务包含 Facebook及其相关服务 Instagram、WhatsApp、Messenger、Oculus等;以及其企业级产品,甚至 Facebook的公司内网。其中,WhatsApp和 Facebook Messenger是公司旗下两款“微信”类即时通信产品,分别在全球范围拥有20亿用户和13亿用户(有重迭),都高于微信(含海外 WeChat)的12.4亿用户和 QQ的6.06亿用户。
这次史无前例的故障,其起因本身就是 Facebook在疫情后不得不开展大量远程工作,导致检修员工不在现场,让事故持续拖延下去。而其结果,是让全球不计其数的中小企业乃至政府部门的远程工作受到严重影响,造成一波又一波的次生灾害。
世纪新冠疫情让人们不得不留在家中,依赖互联网完成大部分工作和人际交往,原本临时的远程办公措施逐渐常态化和永久化,也让人们憧憬新生活方式的可能。但只需要一次简单的服务中断,这一切就都有可能被打回原点。长达6小时的 Facebook大宕机,正是让我们重新反思这一切的绝佳时机。
发生了什么?
根据目前能掌握的信息,这次 Facebook的大规模故障应该是从一次例行维护开始的。
Facebook主管基础设施的副总裁贾纳丹(Santosh Janardhan)说,他们在维护过程中发出的一条命令,无意中关闭了通往世界上所有 Facebook数据中心的骨干网连接。
围绕此事,主要有两个不同的阴谋论。
一是此事正好赶在有位“吹哨人”就 Facebook及 Instagram“无视儿童安全”上美国国会听证会的前夕,6个小时也许够用来“毁尸灭迹”;
另一说是有15亿份近期的 Facebook用户个人资料流出,有人说黑市每100万个用户资料开价5000美元。6个小时同样也许可以用来补救或者掩盖什么。
目前来看,因为“吹哨人”而自导自演宕机的可能性小到几乎为0。官方一再解释,此次宕机并不是黑客攻击导致,也没有证据显示有用户数据是因此事而泄露。
不过,“如无必要,勿增实体”。这起事件是一次单纯的误操作所致,也许是一种更简单也更靠谱的解释。
除 Facebook官方之外,负责第三方公共 DNS解析和 CDN服务的 CloudFlare也在官方博客分析,从外部观察,就是 Facebook的 BGP(边界网关协议)出的问题。
通俗的说,DNS是互联网的“地图”,用来告诉你“x在什么地方”;而 BGP是这一“地图”的“导航”部分,告诉你“怎么走去 x最快”。
要准确理解这一概念,首先要明白一点:
我们现在所称的“互联网”,字面意思是“网际(inter-)网络(net)”,也就是“网络的网络”,是无数张小网络如“岛屿”般彼此连接的后果。这些小网络可能是“中国电信”、“清华大学”或者“x公司北京办事处”。
相对于全球所有联网电脑而言,一整个国家——比如中国或俄罗斯——的全国网络也算是一张巨大的小网络,通过海底电缆等“桥梁”同其它外“岛”相连。但由于它们遵守相同的协议,所以联网方法完全相同。
BGP就是要告诉用户,在地理意义上,你必须经过某些“岛”和“桥梁”才能到达目的地。一般来说,BGP会智能地选择多种不同路线中距离最短的那一条,当然“最短”不意味着“最理想”,因为有些“桥梁”比如5G数据连接是收费的。
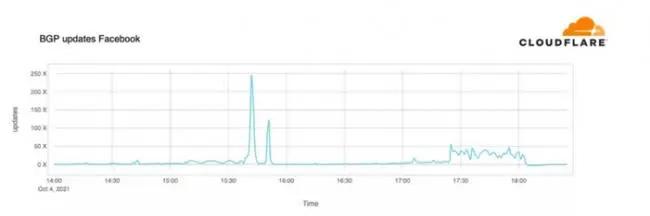
当 Facebook的 DNS服务器注意到问题,就自动停止继续分发 BGP路由信息,等待连接恢复正常。因为全球各地设备无休止的发起不成功的访问请求,会导致对上级 DNS服务器更严重的冲击,让影响扩散得更严重。
这样的事情曾在中国发生过一次。2009年5月19日,两个盗取游戏资产的黑客私斗,导致第三方域名解析服务 DNSPOD被攻击到瘫痪。中国电信停止了对其的网络服务,致使其无法为域名提供解析服务,诸多采用 DNSPOD服务的网站无法访问。
恰好当时全国装机量约1.2亿台的影音播放器“暴风影音”会定期自动访问服务器检查更新,也因为 DNSPOD故障而不断发起域名解析请求,最终干掉了整个电信运营商的本地域名服务器,引发了全国大断网。
在本次事件中,Facebook内部的 DNS服务器本身仍在工作,但主动选择停止解析,以保护更大范围内的网络。虽然修理它并不是什么难事,然而一系列连锁反应使问题进一步恶化。
怎么会这么严重?
缺乏网络连接和域名解析丢失,切断了远程工作的 Facebook工程师和服务器的联系,也禁用了许多他们平常使用的检修工具。一位 Facebook内部人士在 Reddit爆料,当时的情况是:
会修的人连不上路由器也没有登录权限,
有权限的人不会修也连不上,
唯一在机房能物理接触到路由设备的员工没有权限也不会修。
由于内部通讯工具也掉线了,这三波人协作困难,雪上加霜。
公司内部的混乱是全方位的。员工之间本来用公司自己的通讯工具沟通,有时即使需要访问友商业务如谷歌文档和 Zoom会议软件,也要求使用 Facebook账号单点登录。系统崩溃让这一切都陷入停顿。
有的员工在事发之前已经用公司账号登录到谷歌文档等环境,受影响尚且较小;有的急忙上线,却发现自己只能用基于微软 Outlook的工作邮箱、苹果的 Facetime等各种各样的替代服务与同事联系。
新浪科技驻硅谷记者郑峻写道:
“一位 FB朋友说,今天大家都很尴尬,不知道发生了什么,也不知道该做什么,只好假装什么都没有发生,在给一家不存在的网站工作。”
修复工作很显然无法远程完成,工程师们紧急“打飞的”到加州的主数据中心参与维修。在此期间,一些员工并不能使用门禁进入公司大楼和会议室,而这些地方的门只能用门禁卡刷开,没有钥匙孔。
The Verge甚至曾一度获得更戏剧性的消息——因为门禁卡失效,工程师只能带着切割机,强行锯开数据中心的服务器铁笼。不过后面这个报道未经证实,被撤回了。
不过一旦人都被“物理传送”到了合适的位置上,事情相对就好办多了,只需要“激活安全访问协议”而不是动用电锯。
只不过,就算已经解决问题,也必须逐渐一点点地“开闸放水”,否则一次性打开所有通路就如同“8个明星并发出轨”,会导致更多的系统崩溃。负载必须逐步增加,除美国以外地区的其他用户要等更久才恢复访问。
最终,一切又大致恢复了正常,包括 Facebook最多曾下跌5%的股价。




















{kind=link}