
Midjourney这回可以说是惊艳众人了,不过也有网友好奇,另一位重量级选手Stable Diffusion表现又会如何?
这不,有位网友便用Stable Diffusion搞了个镜像:

效果似乎也不错?
效果为何如此炸裂
Midjourney时隔4个月的更新,为何会让效果一下拉高到如此“吓人”的程度?具体又更新了哪些东西呢?
整体来说,最明显的当属以下三点更新了:
细节更加逼真
更多可以选择的风格
告别不会画手
首先是细节部分,下图从左到右依次是V3、V4、V5生成的效果,可以说是越来越逼近照片效果了。

△图源:arstechnica
不仅如此,在有面部特写时,各种肌肤纹理以及光影效果,比如说反射、眩光和阴影等,V5都能搞定。
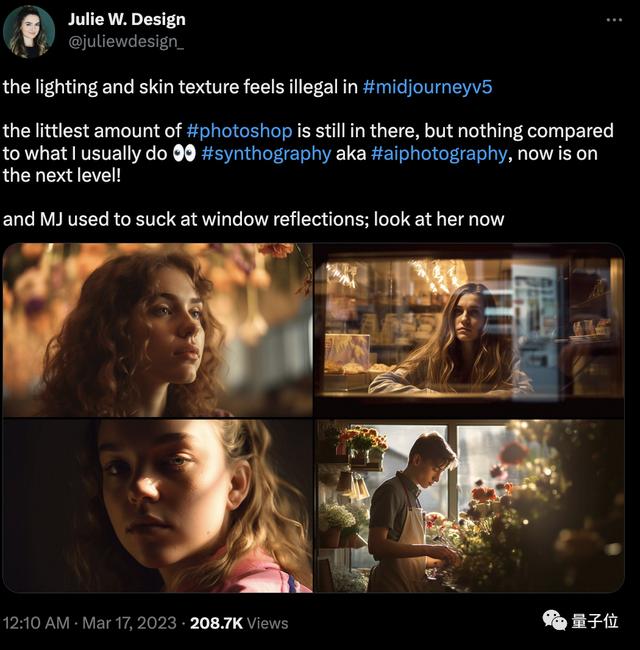
在Discord发布说明中,Midjourney还指出,相较于V4版本,V5版本会有更多的可以选择的风格,分辨率也提升了2倍。
风格的话,可以从0~1000中选择,stylize0=照片,stylize1000=更艺术。
并且V5还会对提示词更加敏感,用更少更精简的文本生成更好的有效的图片。
更更更重要的是,这次升级,Midjourney可算是摆脱掉了“不会画手”标签,想要靠看手指数的多少来判别AI作画已经不管用了(Doge)。
值得一提的是,此前,已经有人通过Stable Diffusion+ControlNet解决了AI画手的问题。
不过,也有网友出来开杠,虽然手指数画对了,但仔细看细节还是能区分出的:
大拇指还是有点过长了。


当然,除了上面这些比较明显的升级之外,Midjourney V5版本还更新了一些小细节。
一位机器学习博主特意列了张表格对V4、V5进行了对比。
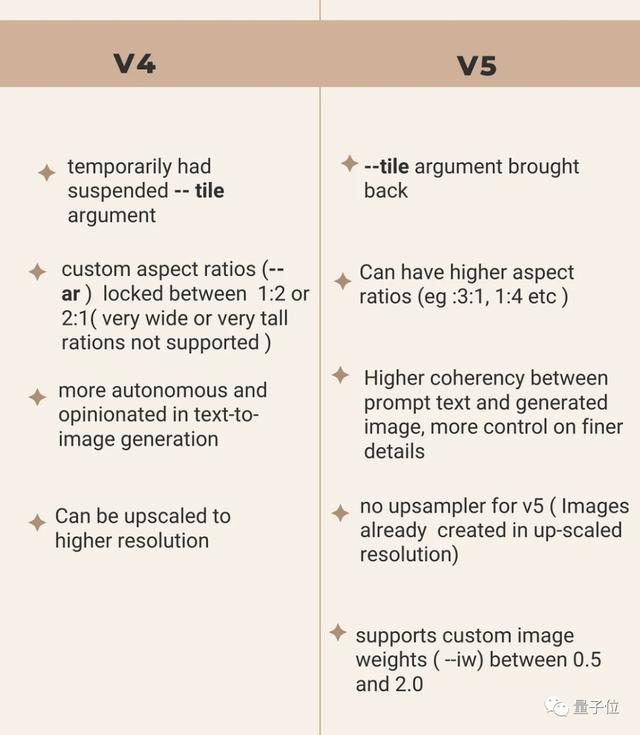
△来自@Lars Nielsen
比如说,在最新的V5版本中,重复式、铺瓷砖式作画功能又回来了,在V4版本中,这项功能被官方禁止。

还有,Midjourney V5生成的尺寸也更加自由,像下面1:3、5:1这种窄长的图像就是V5生成的,甚至1:10的图像它也能生成(如果你想的话)。
反观V4版本,尺寸被限制在1:2~2:1之间。

嗯,这样的话,说不定之后的某个电影创作画面就是Midjourney V5生成的。

此外,V5版本还可以手动调节图像权重,比如输入一张图像,可以手动输入数值来决定它影响最终生成图像的程度。


如何上手试玩
Midjourney目前在公测阶段,通过Discord的机器人指令,AI会根据提示词帮你生成4张你想要的图像。
具体来说,加入测试后,在新手频道中,你可以通过/image指令来输入提示词。
不过,现在想要玩上V5版本的Midjourney,得先充值成为付费用户才行。

(充哪一档都可以)
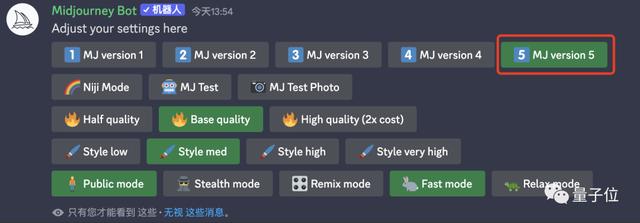
在提示词中加入—v5或者从/settings中选择“V5”,就可以试玩这个最新模型啦~
就像这样:
啊,对了,如果你不知道怎么写提示词,或许可以问问GPT-4。




















{kind=link}