人们听广播的时候,脑海中会幻想出说话者的样貌,
她可能是个面容清秀、身材瘦小的年轻女孩,他也可能是个四十出头、脸长肩宽的中年男人。
猜准年纪和性别,对大部分人来说不难,声音特质已经透露出这些信息。
但猜对具体的容貌却非常困难,人们只能回想脑海里有类似声音的人,把他们的脸贴上去。

人的声音和长相应该是分开的吧……
AI告诉我们:答案不对,有特定声音的人,会有特定的长相。
最近,麻省理工大学的科学家开发出一款AI,它能通过几秒钟的音频,还原出说话者的容貌,相似度非常高。

年龄、性别、种族、五官特征、脸型、发型、胡须造型,这些它能会绘制出来……
这款AI叫作“Speech2Face”,名字说得很清楚,“从话到脸”。
科学家创造它的目的,是想知道人类能在多大程度上,通过一个人的声音推断出他的长相。

乍一听上去,这像看相那样玄学,但背后的道理其实很好理解。
人类说话靠的是振动声带,它是位于喉部的左右对称的两瓣肉。声带的长度和宽度是影响我们音调高或低的主要原因,因为男性的声带较女性更宽,所以音调更低。
声带振动后,声音在我们的胸腔里嗡嗡作响,大部分从喉咙里传出去。
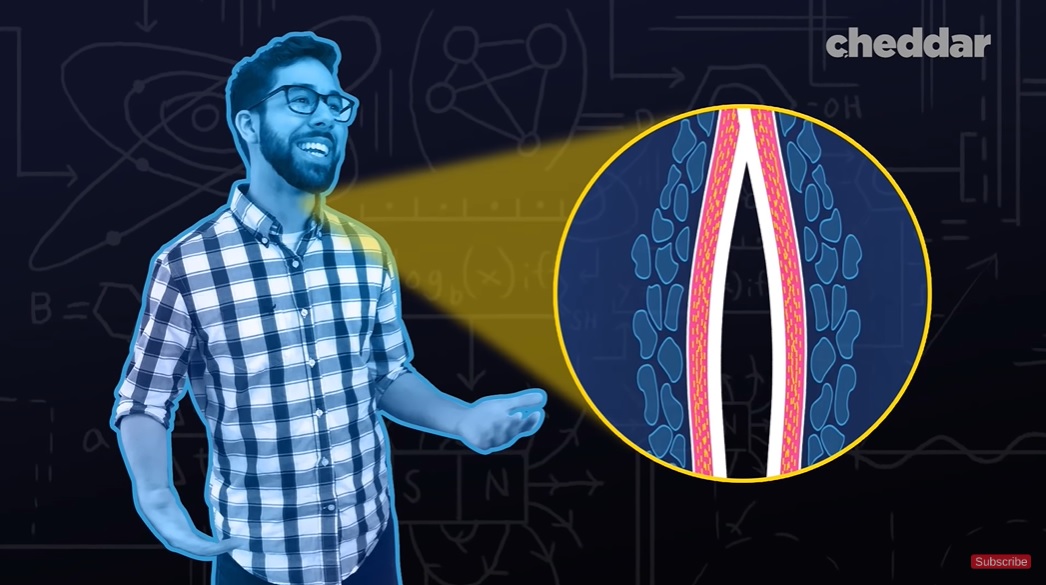
但这不是唯一的传声路径,我们的脸部也充当着声音的扩音器,颧骨、下巴、鼻子、嘴唇等都会振动,它们的厚度、结构不同,发出的声音也不同。
电脑能捕捉到这些细微的声音差别,继而画出说话者的面部特征。
这就是AI工作的原理。

麻省理工的科学家们收集了油管上数百万个视频,里面有十几万个人说话,他们将这些视频输入给Speech2Face。
Speech2Face会把视频中人脸的特征摘出来,制作出一张标准的正面照,这个照片基本等同对方的真人脸。
同时,它还会把声音从声波转成声谱图,然后传给人声编码器,找出其中的声音特征。
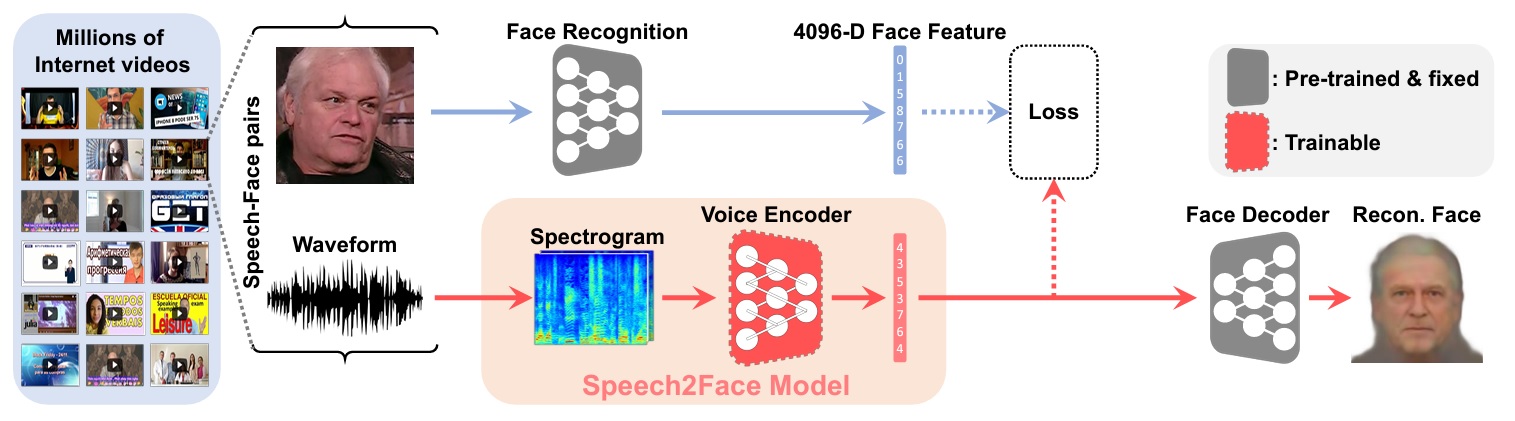
两两相对,Speech2Face就这样学会声音和相貌之间的关联,不需要其他的信息。
在大量视频的训练下,它只需要听3秒或6秒的音频,就能画出人脸。
比如,放美国情景喜剧《神烦警探》中男二霍尔特讲笑话的音频片段,Speech2Face会画出下方右侧的图。

和饰演霍尔特的演员相比,右侧的图脸更宽和胖,但肤色和鼻子形状与真人一样,效果不错。
其他测试对象还有白人老太太、非裔男子、拉美女孩和白人男性,
左边的真人图和右边的AI图对比,都挺像。
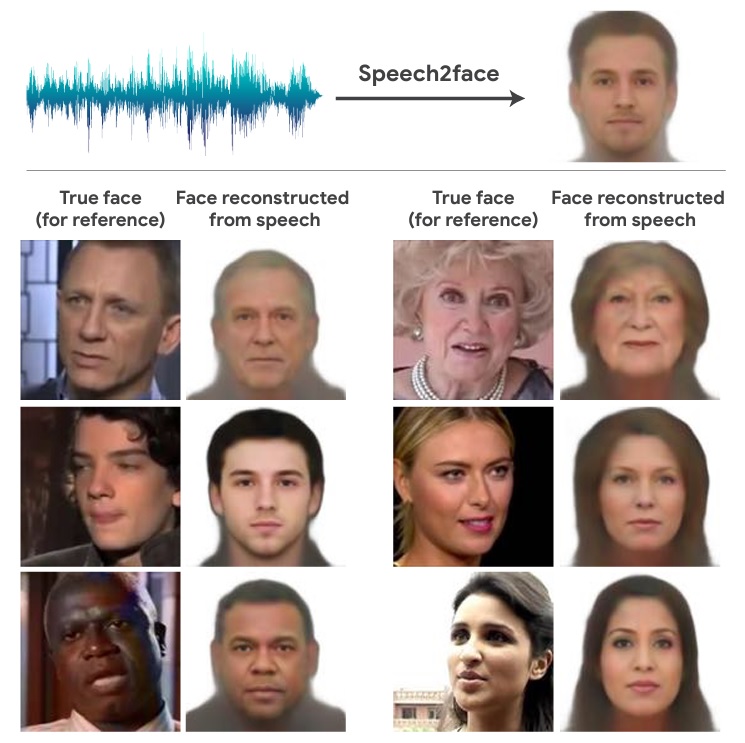
类似的对比图在论文里还有很多,下面这些图的第一列是视频截图,第二列是电脑根据截图转换的正面照,第三列是AI根据声音绘制的图。

将第三列和前两列对比,发现种族、性别、年龄、眉毛、发型和发色基本都对。



为什么眉毛和头发也能相似?它们又不随声音振动。

















{kind=link}