英伟达最近动作不少。先是11月上旬,向我们国内出口了特(yan)供(ge)版的H20芯片,接着一周后就又发布了面向海外的H200芯片。
看得出,这次芯片命名,老黄还是花了点心思的。特供和美版,肉眼可见的十倍差距,应该会令想制裁中国的登哥十分满意。
H200确实很强,H20据说也很受欢迎,那么,国内GPU就真的不行吗?差距到底在哪里?
众所周知的一个差距是在“算力”方面,也就是单位时间能处理的信息。这个差距的弥补主要靠“设计和制造”。芯片制造只能步步追赶,需要设备、材料、工艺等等的综合提升;而设计方面,需要靠积累,但也已经没那么差了。
比如从算力角度来看,国产一款910的产品和H20对比的话,半精度算力还比H20高呢。那差在哪里?
在显性算力的背后,隐性的差距,其实是在“网络”和“存储”,或者统一而言是“带宽”。
如果以厨师做饭来做比喻的话,高算力就相当于手艺精湛的大厨,能做好菜、能高效做好菜;但做菜还需要运输,比如把菜从市场买回来、以及,把菜洗好传给大厨。如果买菜很慢、或者传菜很慢,那么大厨再牛也难为无米之炊。
网络和存储,就是买菜和传菜;它们就是当前限制中国算力大厨的隐性关卡。为什么会这样?又该如何破解呢?
01省掉一步,更快速度
特斯拉有一个超算中心Dojo,作为其智能驾驶的火力支撑。然而,特斯拉FSD V12版本的训练,却并不是依靠Dojo,而依然是英伟达。
马斯克对此称,“目前遇到的最大技术困难,是需要像InfiniBand那样的高速网络连接来并行更大的算力。”
提到网络连接,就得先从美国施乐说起,也就是养活了微软和苹果的那位大哥。在计算机初期,网络连接有各种标准,不容易互相通信。后来,施乐在公司内部使用了一种连接标准,就是以太网的雏形。1982年发布了以太网标准。
以太网标准下,服务器之间的交互流程是应用程序的数据,先到核心内存,再送到网卡,然后通过网卡,送到另一台服务器上。所有的信息对接,都要经过内存转换,增加了CPU的负担,也增加了传输的时延。
这就好比我们打车。乘客打电话给出租车公司,公司再打电话给司机;司机到了之后,也不联系乘客,而是打电话给公司,公司再打电话给乘客。好处是可靠、便于管理。但缺点也很明显,流程太长了,信息来回传递也不方便。
业务量少的时候,没有问题。但一旦数据量太多、需求很多,那么,效率就会有折扣。这对于AI而言,就非常明显了。
大模型就是通过大量数据的大量计算,从而产生了涌现。数据传输快一点,能力也就会更强一点。如果数据都传得很慢,怎么可能大量计算呢。
于是,InfiniBand脱颖而出。
1999年,InfiniBand贸易协会成立,目的就是为了“干掉”传统以太网。目标很大,敌人也很强大,抗争很艰难。以至于2002年的时候,英特尔就从这个协会里退出了,随后微软也退出了。
但成立于1999年的Mellanox还在坚持,2001年还推出了首款产品。InfiniBand的特点是,数据,不经过核心内存而是直接通过网卡连接。
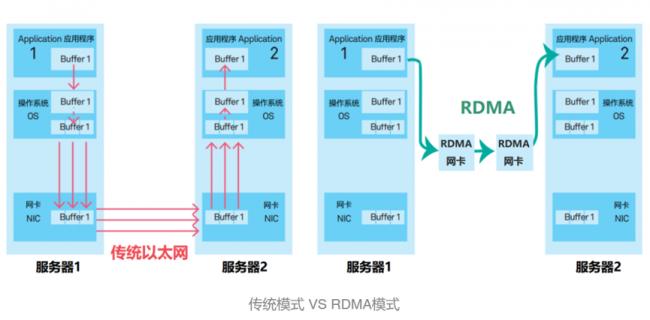
这个模式对于数据中心而言,效果非常好用。因为数据中心的场景很固定,也没有各种需求。所以,Mellanox很快就成为了数据中心网络连接的老大,市占率一度高达80%。2013年,Mellanox还收购了硅光技术公司,让数据传输进一步加快。
Mellanox的高速发展,也吸引了巨头们的关注。GPU的高速并行运算,配合高速数据传输,对于英伟达而言,可谓是:
周董看到了优乐美。
于是,2019年,英伟达(Nvidia)公司豪掷69亿美元,击败对手英特尔和微软(分别出价60亿和55亿美元),把Mellanox捧到了手心里。英伟达也拿到了InfiniBand这个利器,令众人看不惯又干不掉。
但随着英伟达在AI领域的地位越来越显著,“反抗”也随之而来。
超以太网联盟(Ultra Ethernet Consortium)在今年成立,希望用新的协议来抗争。UEC集结了AMD、Arista、博通、思科等设备商,以及Meta、微软等云厂商。而协议的标准也比较明确,“打不过就抄过来”。
显然,在网络连接端吃亏的,也不只是我们的算力公司,马斯克不也抱怨了么。谁让英伟达眼光好呢,只能等超以太网干活了。
02先进封装,黄金万两
传菜为什么也受限了呢?说起这个,就不得不提冯·诺依曼,一位奠定了现代计算机架构的大师,一位让无数学子重考的大师。在冯·诺依曼架构中,有“运算”、“存储”、和“输入输出”等三大类设备,也就是炒菜、存菜、传菜。

冯·诺依曼架构
这种架构下,存储和CPU频繁的交换数据,一下子就提高了存储的地位,也让这个架构里存在了“内存墙”。那么如何打开一扇窗呢?
这就是H200/H100的另一个核心力,HBM(High Bandwidth Memory,高带宽内存)存储芯片。
HBM是2014年由AMD、SK海力士共同发布的,就是用TSV硅通孔技术,把多个DRAM存储芯片堆叠起来,并与GPU、CPU或者ASIC封装在一起,从而提高容量,以及更快的并行数据处理速度。
快是有一定道理的,首先,存储就是逻辑层上方,从隔壁楼到上下楼,打个招呼就行,自然方便多了,功耗也降低不少。另外,统一封装,互联上的延时也更低。效果也很显著。
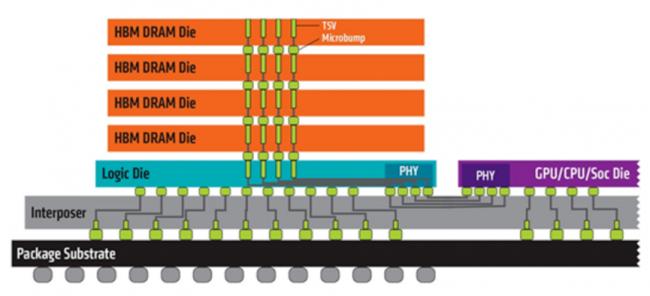
HBM的基本结构:左侧彩色的5层结构为 HBM封装
比如一组数据显示,HBM3的带宽可以达到819 GB/s,而GDDR6的带宽最高只有96GB/s,CPU常用DDR4,带宽也只有HBM的1/10。因此,英伟达、AMD都选择了HBM技术来配合。英伟达的H200更是选择了HBM3的升级版HBM3e。
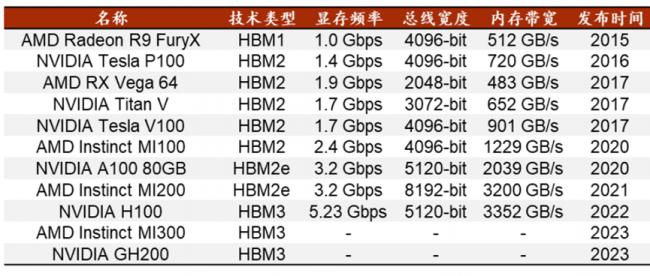
HBM成各家最爱
HBM产品市场份额,目前是海外独享。海力士占比50%,三星占比40%,美光占比10%。中国企业目前仍在DRAM产品领域追赶。
最简单的事情,却往往最难。好比说,炒股赚钱,最简单的方法就是“低买、高卖”,但赚钱的人不足10%。HBM也是如此,虽然看图片,好像挺简单的,但实现起来,则是困难重重。
首先是设计,人才是稀缺的。其次是生产。HBM芯片的生产,主流的路线是台积电的CoWoS(chip-on-wafer-on-substrate)先进封装,也是2.5D封装。先把芯片集成在一起,再封装到基板上。哪一步都不容易。
好消息是华为国产GPU也可以用HBM产品,不太好的消息是最高阶的产品,我们还是拿不到。所以,面临随时可能的断供,存储芯片依然需要持续发力。
03投桃报李,讲点义气
无论是算力、还是网络、或者高带宽内存,其实都有一个核心要素是:用起来。
比如台积电的CoWoS技术开发早期,也遭遇过“冷眼”。公司希望价格是7美分/平方毫米,但客户高通却只愿意支付1美分/平方毫米。巨大的差异,导致公司不得不开发个平替产品。幸好当时自研芯片的苹果,给了台积电机会,于是有了CoWoS工艺的成熟、普及,以及再研发。
提起英伟达,一个公认的护城河便是CUDA生态。生态,意味着参与者迁移成本很高,比如开发者已经熟悉了英伟达的开发套件,再去熟悉其他公司是有难度的。就跟用惯了微信,就很难再换其他聊天工具一样。

要打破生态的壁垒,核心也是要让一批人在新的环境里用起来。
最近互联网圈也爆出了不小的新闻,美团、网易、阿里、字节等等公司,都启动或完成了和鸿蒙系统的适配。只有越来越多的企业支持,系统才有生存空间。
当然,新生态,尤其在后起步的芯片领域,许多环节会不如成熟生态好用。但即使是英伟达,前期搭建CUDA也花费了数十年心力,顶着不小的质疑。因此,对于国产芯片的支持,难免需要一些情怀,用爱发点电。
不过,对于被支持的企业,要记得投桃报李。
虽然目前中国的算力,依然和海外有不小的差距。但庆幸的是,社会已经逐渐形成了共识:
1美分/平方毫米,也就是7万元/平方米的芯片,比7万元/平方米的房子,更能产生持久的生产力。



















{kind=link}